
Reasoning capabilities of large language models: a systematic review and meta-analysis of benchmarks, methods, and emergent behaviours (2018–2025)
Keywords:
Large Language Models, Chain of Thought, Systematic Review, Meta-Analysis, Gpt 4, Natural Language Inference.Abstract
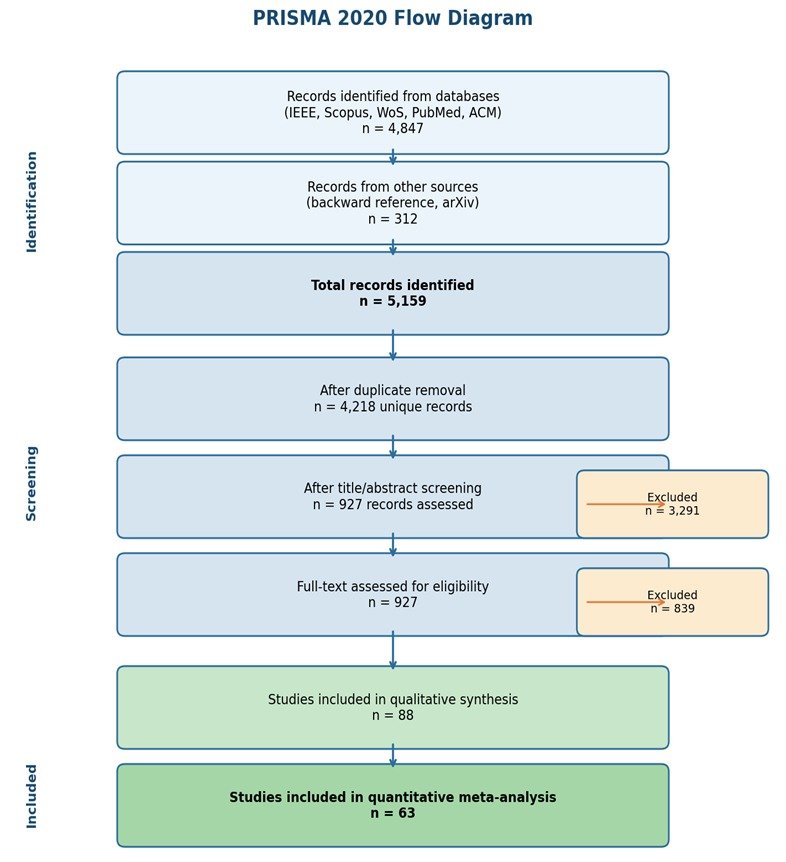
Large Language Models (LLMs) exhibit solid reasoning capabilities in various domains, including mathematical reasoning, commonsense reasoning, logical inference, scientific question answering, and code generation. But it is not known how these reasoning abilities develop, and how effective they are in various situations. The aim of this systematic review and meta-analysis was to assess the available evidence about LLM reasoning performance up to the end of December 2025. Five major databases (IEEE Explore, Scopus, Web of Science, PubMed and ACM Digital Library) were searched, according to PRISMA 2020. The qualitative review included a total of 88 studies; and, 63 studies included quantitative benchmark data for meta-analysis. The Cochrane framework was used to assess the risk of bias. The results show that LLMs excel in various reasoning tasks, such as mathematical reasoning, commonsense question answering and code generation. The chain of thought prompting techniques consistently enhanced the accuracy of reasoning over the other prompting techniques. On Multistep tasks, tool augmented and self-reflective models performed very well. Despite the progress, LLMs also have limitations when input data is adversarial, when there are distributional shifts, and when the input is compositional. Also, there is significant differences between the studies so the results of the benchmarks cannot be easily generalized. From the review, it is clear that LLM reasoning capabilities are substantial and are making rapid progress, but there are also critical challenges. For the future, the development of more robust, reliable, interpretable and evaluation methods are required for ensuring reliable reasoning performance in real world applications.
Published
How to Cite
Issue
Section
Copyright (c) 2026 Prof. Tareq N. Hashem

This work is licensed under a Creative Commons Attribution 4.0 International License.

