
Implementation of FPGA-based Accelerator for Convolutional Neural Networks
Keywords:
Convolutional Neural Network, Field Programmable Gate Array, Neural Network.Abstract
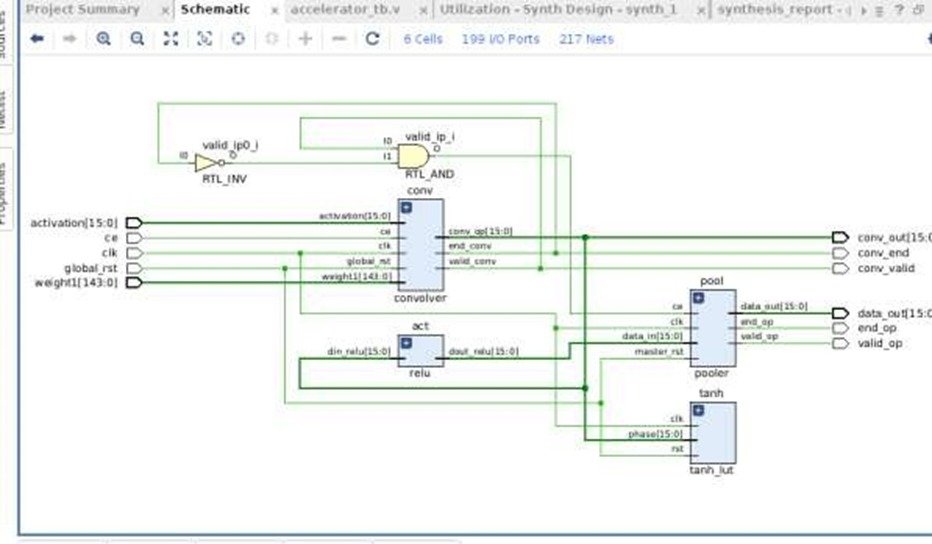
This research paper presents a novel FPGA-based accelerator tailored for Convolutional Neural Networks (CNNs), specifically implemented on the Virtex-7 evaluation kit. By harnessing the inherent parallel processing capabilities of FPGAs, the architecture of the accelerator is meticulously crafted using Verilog. The FPGA implementation demonstrates a resource-efficient design, making use of 588 Look-Up Tables (LUTs) and 353 Flip Flops. Notably, the efficient utilization of these resources signifies a careful balance between computational efficiency and the available FPGA resources. This research significantly contributes to the field of hardware acceleration for CNNs by offering an optimized solution for high-performance deep learning applications. The presented architecture serves as a promising foundation for future advancements in FPGA-based accelerators, providing valuable insights for researchers and engineers working in the domain of hardware optimization for Convolutional Neural Networks.
Downloads
Published
How to Cite
Issue
Section
Copyright (c) 2024 Abdullah Farhan Siddiqui, Prof. B. Rajendra Naik

This work is licensed under a Creative Commons Attribution 4.0 International License.

